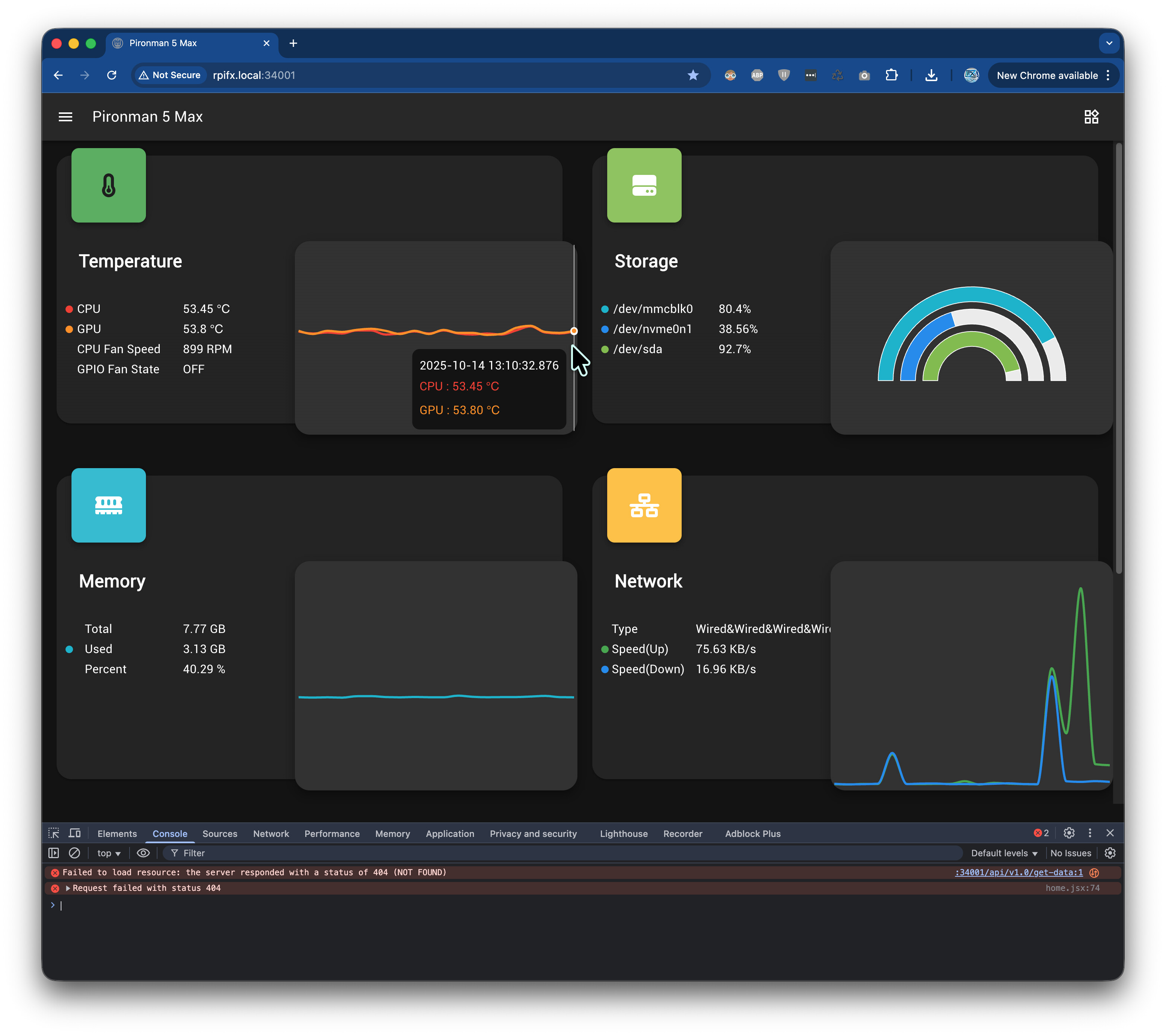
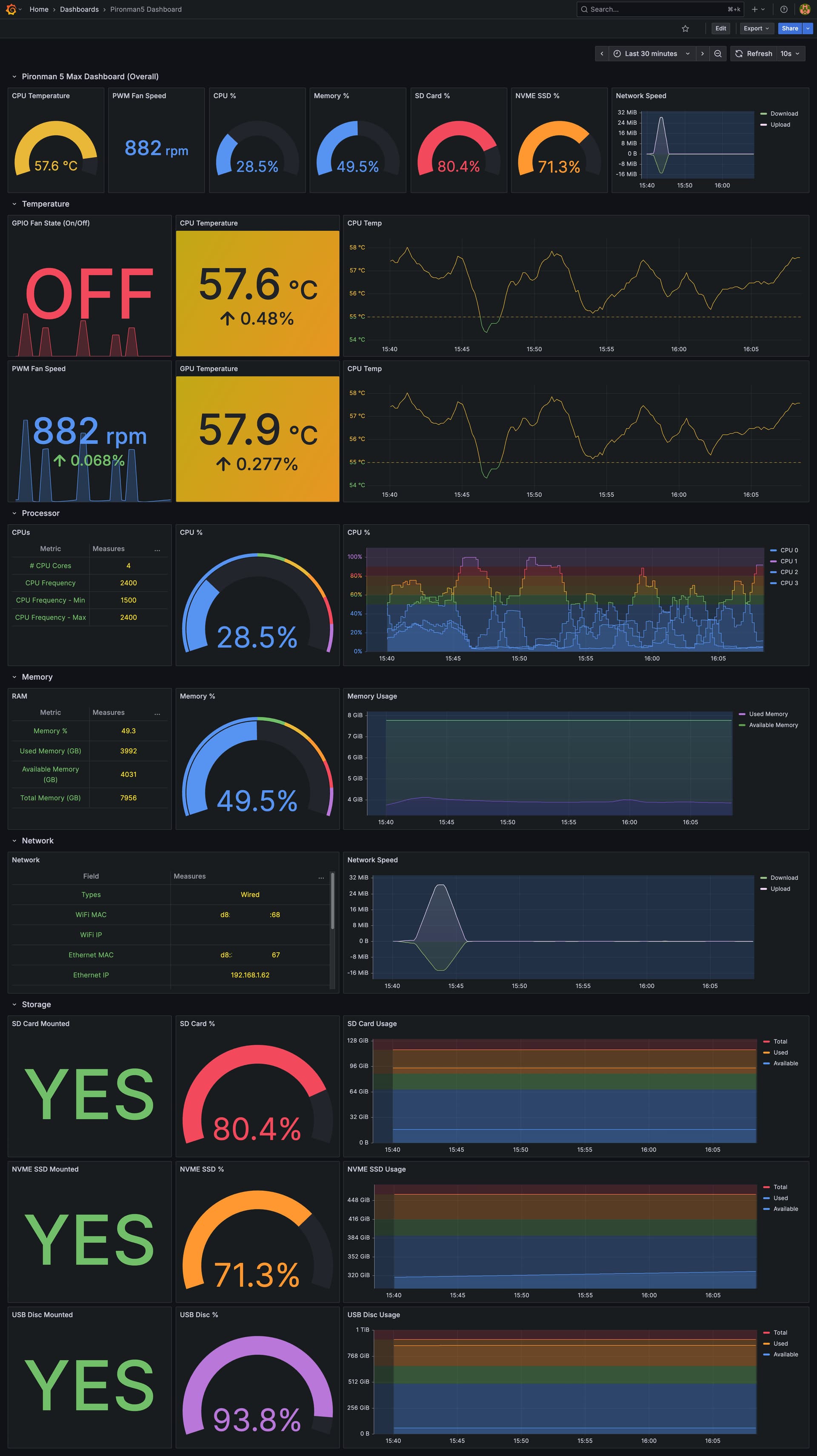
Hi @SunFounder_Moderator
I think I found the issue at least about pironman & influxdb’s extreme resource usage and crashing the pironman dashboard.
it seems influxdb every second retrieve the sensor data and also at the same time (1 second) it Continuously writes data points every few seconds to influxdb which has also no retention policy so that it consumes lots of cpu, memory and after a while start crashing.
1. optimize InfluxDB
Limit how long data is stored (default was unlimited) so that change it to 1d or 7d up to you.
$ influx
> USE pironman5;
> CREATE RETENTION POLICY "1d" ON "pironman5" DURATION 1d REPLICATION 1 DEFAULT;
> exit
$ sudo systemctl restart influxdb
2. optimize pironman (Write Frequency)
Reduce Write Frequency, Change the pironman Dashboard’s data_interval period from 1 second to 10 seconds or more.
sudo nano /opt/pironman5/venv/lib/python3.*/site-packages/pironman5/config.json
// Change **data_interval** value from 1 to 10 (or 60)
Recommended Values
- data_interval = 1: Default (writes to InfluxDB every second) - High resource usage
- data_interval = 5: Good balance - reduces writes by 80%
- data_interval = 10: Recommended for resource savings - reduces writes by 90%
- data_interval = 60: Minimal resource usage - only writes once per minute
sudo systemctl restart pironman5
Check the final configs.
$ sudo pironman5 -c
{
“system”: {
“data_interval”: 10, // Changed from 1 to 10 (or 60)
“rgb_color”: "
“oled_sleep_timeout”: 0,
“debug_level”: “INFO”
…
}
}
voila!
dashboard working after 5 hours later and still showing the sensor values as 10 seconds window frames.
(btw, this message still continue on console log Failed to load resource: the server responded with a status of 404 (NOT FOUND) :34001/api/v1.0/get-data but doesn’t affect the dashboard)
Optional Settings for influxdb
sudo nano /etc/influxdb/influxdb.conf
[data]
cache-max-memory-size = “25m” # Reduce from default 1GB
cache-snapshot-memory-size = “25m”
cache-snapshot-write-cold-duration = “10m”
compact-full-write-cold-duration = “4h”
max-series-per-database = 10000
max-values-per-tag = 1000
[coordinator]
write-timeout = “10s”
max-concurrent-queries = 0
query-timeout = “0s”
log-queries-after = “0s”
max-select-point = 0
max-select-series = 0
max-select-buckets = 0
[http]
enabled = true
bind-address = “:8086”
auth-enabled = false
log-enabled = false # Disable HTTP logging
max-row-limit = 0
max-connection-limit = 0